Claude Sonnet 5 is the model I expected Anthropic to ship after the Fable 5 drama: less dramatic than Mythos, more practical than a tiny upgrade, and clearly aimed at daily agent work.
Anthropic launched Claude Sonnet 5 on June 30, 2026. The headline is not that Sonnet suddenly beats every Opus-class model. It does not. The useful story is cost-performance. Sonnet 5 moves much closer to Opus 4.8 on agentic work, keeps Sonnet pricing, and becomes the new default model for many Claude users.
That matters for the way I use AI agents. I care less about one-shot chat answers and more about whether a model can inspect a repo, use tools, stay on task, and finish a job without making a mess.
The benchmark snapshot
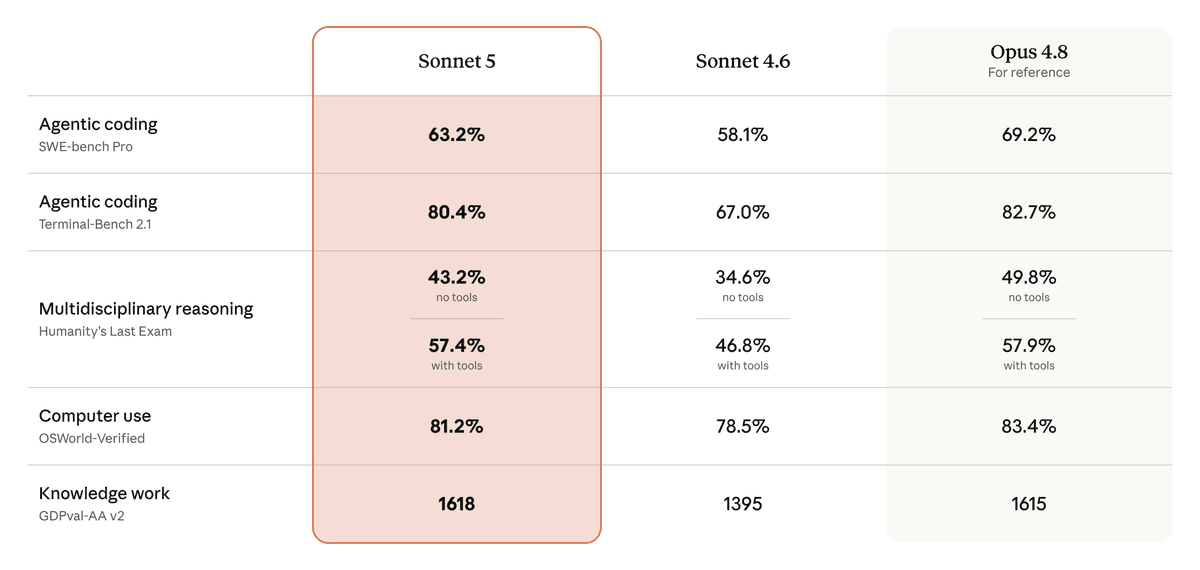
Anthropic's launch table compares Sonnet 5 with Sonnet 4.6 and Opus 4.8. The pattern is clear: Sonnet 5 is a real jump over Sonnet 4.6, but Opus 4.8 still leads on some of the hardest agentic tasks.
| Benchmark | Sonnet 5 | Sonnet 4.6 | Opus 4.8 |
|---|---|---|---|
| --- | ---: | ---: | ---: |
| SWE-bench Pro | 63.2% | 58.1% | 69.2% |
| Terminal-Bench 2.1 | 80.4% | 67.0% | 82.7% |
| Humanity's Last Exam, no tools | 43.2% | 34.6% | 49.8% |
| Humanity's Last Exam, with tools | 57.4% | 46.8% | 57.9% |
| OSWorld-Verified | 81.2% | 78.5% | 83.4% |
| GDPval-AA v2 | 1618 | 1395 | 1615 |
The strongest signal is Terminal-Bench 2.1. Sonnet 5 jumps from Sonnet 4.6's 67.0% to 80.4%, close to Opus 4.8 at 82.7%. That is the kind of gap closing that matters for coding agents because terminal work punishes models that cannot plan, recover, and use tools.
SWE-bench Pro is more conservative. Sonnet 5 improves over Sonnet 4.6, but Opus 4.8 remains ahead. I would read that as a procurement answer, not a hype answer: use Sonnet 5 for normal agent runs, keep Opus for the cases where the extra reliability is worth the price.
Cost-performance is the real launch story
Anthropic also published cost-performance charts for BrowseComp and OSWorld-Verified across effort levels. These are more useful than a single top-line score because Sonnet 5 now gives teams a knob: spend less for medium effort, or push effort higher when the task needs it.
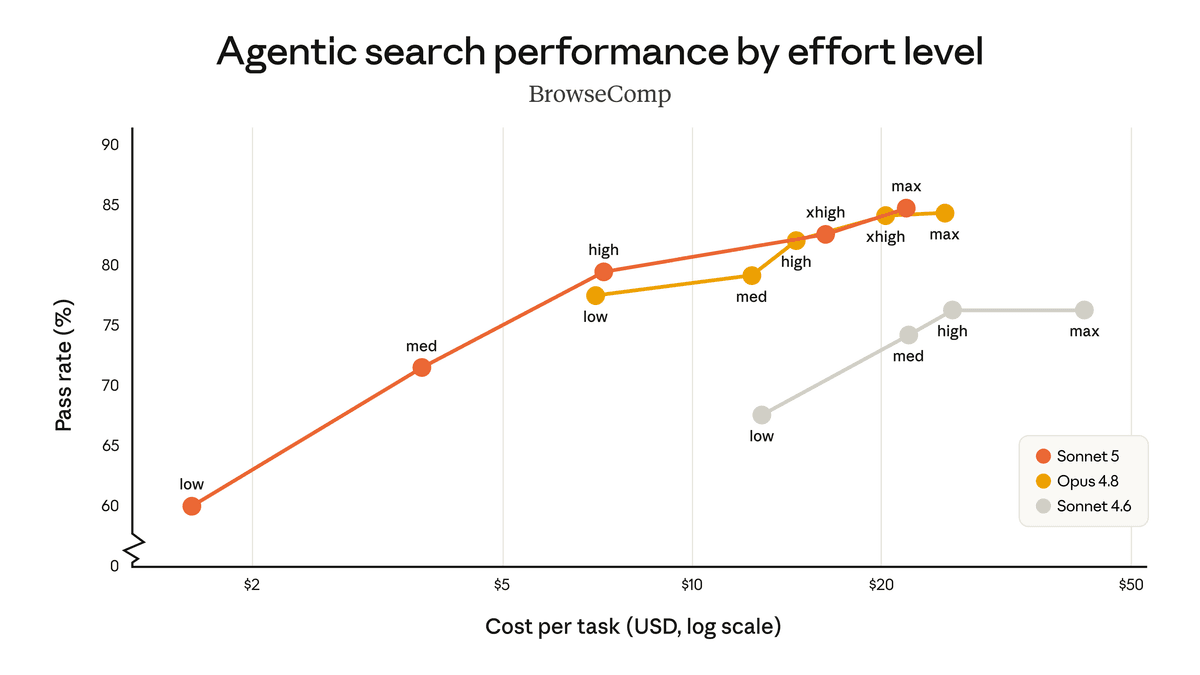
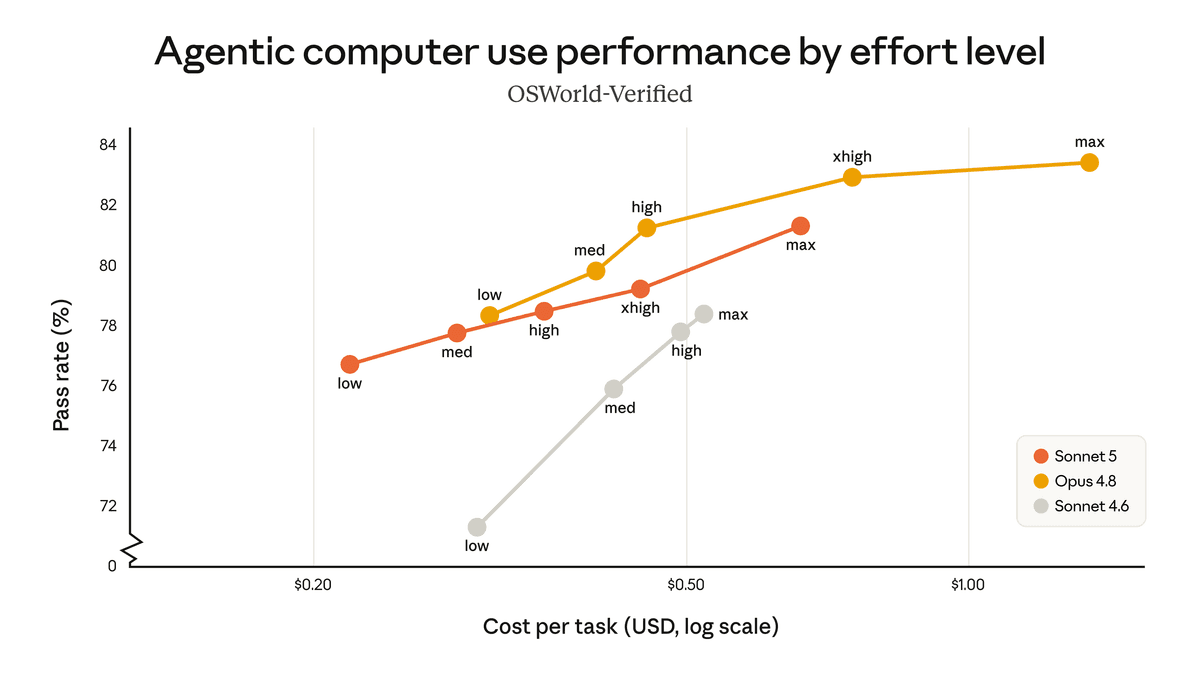
This is exactly where a Sonnet-class model should win. Opus exists for harder reasoning, but most workflows need enough intelligence at a price where you can run the agent repeatedly. Debugging, browser QA, repo inspection, content operations, and small automation tasks all benefit from a model that is cheaper to run without dropping the thread halfway through.
Anthropic says Sonnet 5 is available at introductory API pricing of $2 per million input tokens and $10 per million output tokens through August 31, 2026. After that, it moves to $3 input and $15 output per million tokens. That standard price matches Sonnet 4.6 per token, but there is a catch: the docs say Sonnet 5 uses a new tokenizer that produces about 30% more tokens for the same text.
So I would not call the migration automatically cost-neutral. I would re-count prompts before moving long-running agents from Sonnet 4.6 to Sonnet 5.
What changes for developers
The model ID is `claude-sonnet-5`. Anthropic describes it as a drop-in upgrade from Sonnet 4.6, but the docs list behavior changes that matter in real apps.
First, adaptive thinking is on by default. If you do not pass a thinking field, Sonnet 5 still runs with adaptive thinking. You can disable it, but the default changed.
Second, manual extended thinking is gone. The old `thinking: { type: "enabled", budget_tokens: N }` pattern returns a 400. Anthropic wants developers to use adaptive thinking with the effort parameter instead.
Third, non-default sampling parameters are rejected. Requests that set `temperature`, `top_p`, or `top_k` to non-default values return a 400. That is a real migration issue if your wrappers set sampling defaults automatically.
The good part: Sonnet 5 supports a 1M token context window by default and up to 128k output tokens. For repo-scale work and long context workflows, that gives agents more room to inspect before editing.
Safety and cyber benchmarks
Anthropic is positioning Sonnet 5 as safer for ordinary agent use than Sonnet 4.6. The launch post says Sonnet 5 has a lower rate of undesirable behavior than Sonnet 4.6 and is safer in agentic contexts.
The cyber chart is the more important limit. Anthropic says it did not deliberately train Sonnet 5 on cybersecurity tasks. On a Firefox 147 exploit-development evaluation, Sonnet 5 never produced a full working exploit. It scored 0.0% on working exploit success and 13.2% on partial success. Opus 4.8 and Mythos 5 are much stronger on that eval, which is exactly why Anthropic keeps different access and guardrail policies around the higher-risk models.
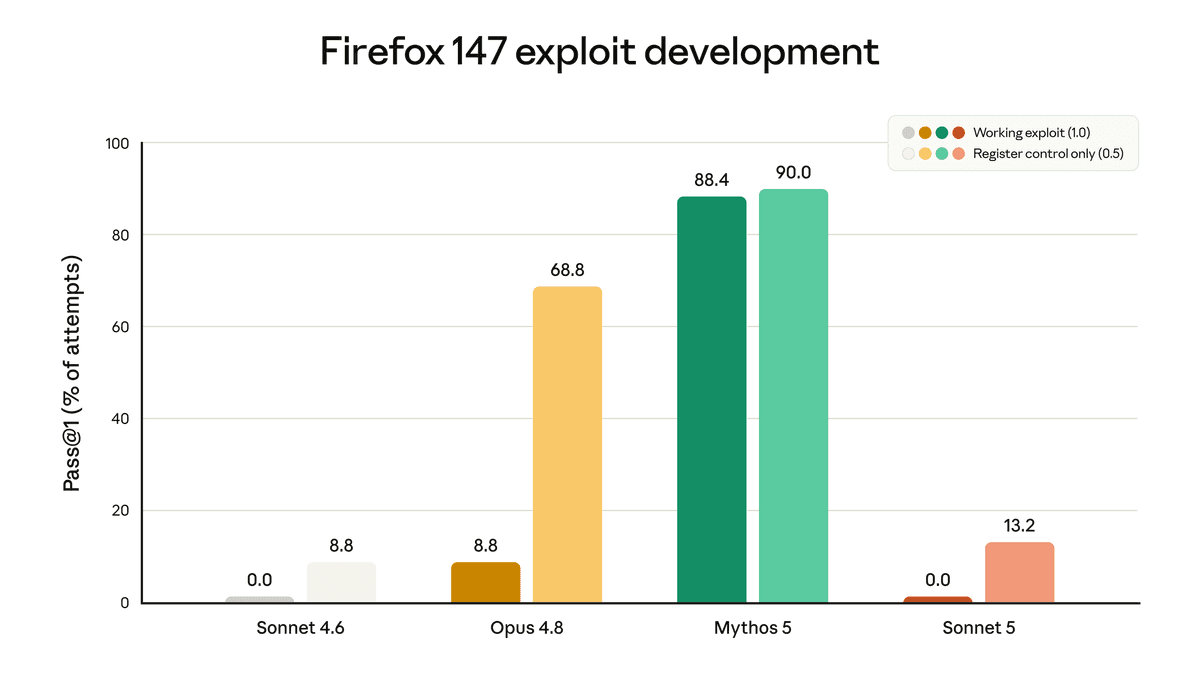
That framing makes sense. Sonnet 5 should be strong enough for normal coding and agent work, but not optimized for dangerous cyber capability. Anthropic also says Sonnet 5 launches with real-time cybersecurity safeguards enabled by default.
My first read
I would treat Claude Sonnet 5 as the new default workhorse model for Claude agents.
It is not the model I would pick for every hard codebase problem. Opus 4.8 still wins in some agentic coding and computer-use benchmarks. Fable 5 is still the more dramatic frontier story. But Sonnet 5 lands in the part of the market most builders actually feel: price, context, tool use, and whether the agent keeps going.
For Claude Code, this is probably the most interesting angle. A cheaper model that can run longer, use tools better, and stay close to Opus on many tasks changes the economics of agent loops. You can reserve Opus-class models for review, hard debugging, or high-risk changes, while using Sonnet 5 for the main execution pass.
That is how I would test it first:
A model that scores well on benchmarks still has to behave inside a real workflow. It has to read the current files, avoid unrelated edits, run checks, and stop when the next step needs a human decision. I wrote about that operating style in my Claude Code /loop and /goal article→.
Verdict
Claude Sonnet 5 looks like Anthropic's cost-performance answer for the agent era. It narrows the gap to Opus 4.8 without pretending to replace it everywhere.
The benchmarks say it is much stronger than Sonnet 4.6 on terminal work, tool use, computer use, knowledge work, and reasoning. The docs say developers need to watch token counts, adaptive thinking, and sampling-parameter changes. The safety story says Anthropic wants Sonnet 5 to be powerful for everyday agents without giving it the same cyber profile as Opus or Mythos.
That is a practical launch. I will test it like a practical model.


