I missed Claude Fable 5 more than I expected.
That sounds strange to say about a model that had a messy launch window, got pulled back, and became wrapped in export controls and cyber-safety arguments within days. But Fable 5 was the Claude model I wanted for hard agent work: repo inspection, long coding loops, tool use, debugging, and the kind of tasks where the model has to keep going without turning the workflow into noise.
Anthropic now says Fable 5 is coming back globally. The short version: the US government applied export controls to Claude Fable 5 and Claude Mythos 5 on June 12, 2026. Anthropic suspended access because it could not verify nationality in real time. On June 30, Anthropic said those export controls had been lifted, and Fable 5 would start returning globally on Wednesday, July 1, 2026.
I am glad this chapter is nearly over. I want to test the model in normal work again, not read another week of speculation about whether it will ever come back.
Why Claude Fable 5 matters
Fable 5 is not another small model refresh. Anthropic describes it as a Mythos-class model made safer for general use. That means the underlying capability is close to the more restricted Mythos 5, but Fable 5 ships with stronger safeguards and classifiers.
The launch benchmarks explain why people cared so much when access disappeared.
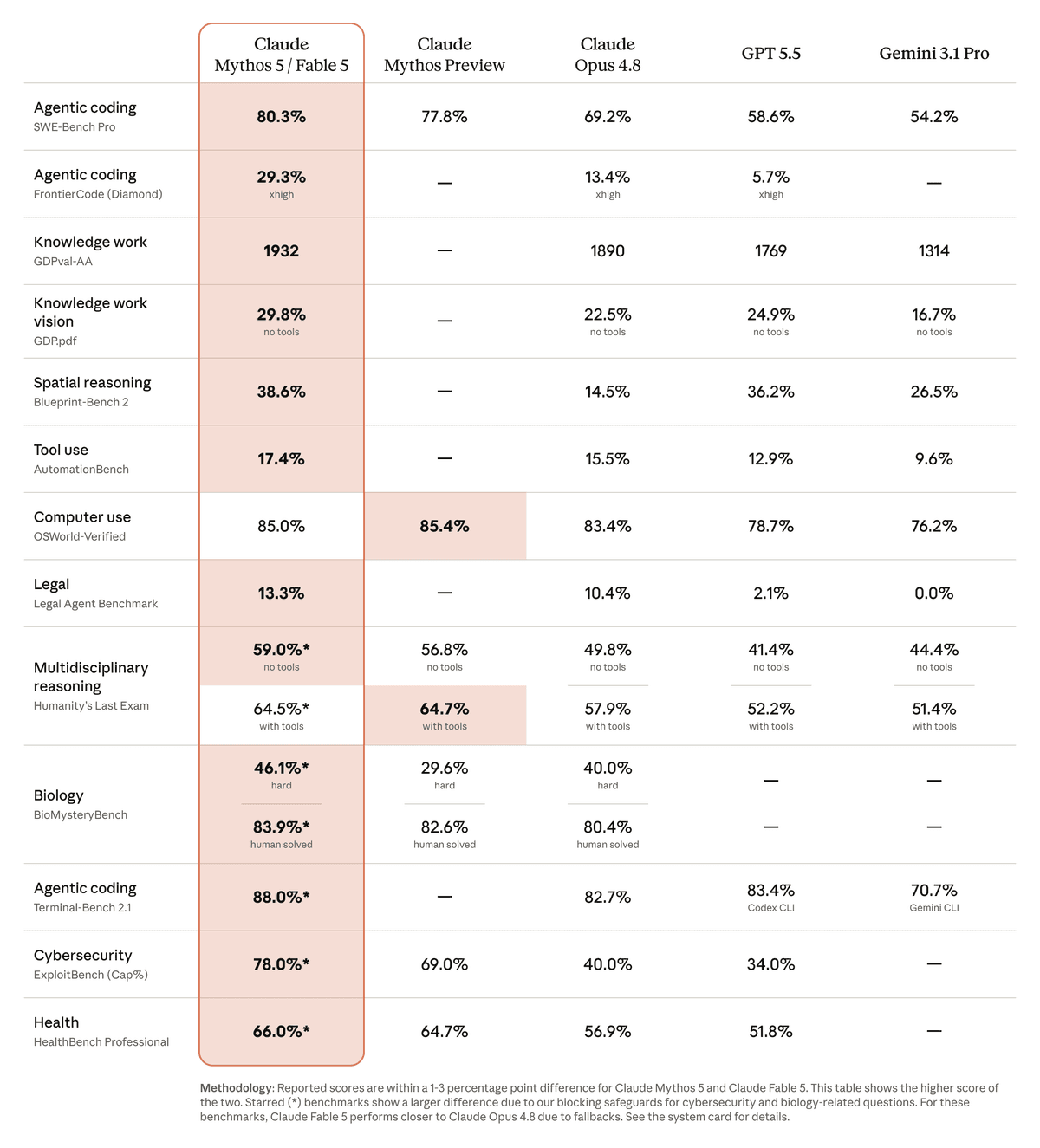
| Benchmark | Claude Mythos 5 / Fable 5 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| --- | ---: | ---: | ---: | ---: |
| SWE-bench Pro | 80.3% | 69.2% | 58.6% | 54.2% |
| FrontierCode Diamond | 29.3% | 13.4% | 5.7% | - |
| OSWorld-Verified | 85.0% | 83.4% | 78.7% | 76.2% |
| Terminal-Bench 2.1 | 88.0%* | 82.7% | 83.4% | 70.7% |
| ExploitBench | 78.0%* | 40.0% | 34.0% | - |
| HealthBench Professional | 66.0%* | 56.9% | 51.8% | - |
The asterisks matter. Anthropic says some starred benchmarks show a larger gap between Mythos 5 and Fable 5 because safeguards and fallback behavior affect Fable. So I would not read the table as pure raw model capability for every user request. I would read it as the reason Fable 5 became so interesting: it is close to the Mythos tier while still being the model Anthropic wants normal users and developers to access.
For my own work, the strongest signals are SWE-bench Pro, Terminal-Bench 2.1, and OSWorld-Verified. Those map closer to agentic coding and computer-use workflows than generic chat benchmarks. Fable 5 looks built for long, messy tasks where the model has to inspect state, use tools, recover from errors, and keep enough context to finish.
The new safeguard deal
The return is not a simple switch back on.
Anthropic says it trained an improved safety classifier after an Amazon report showed a way to bypass Fable 5 safeguards around vulnerability-related requests. Anthropic argues the report did not reveal unique Mythos-level cyber capability, but the company still moved to block the described behavior.
The new classifier blocks the specific technique from that report in more than 99% of cases, according to Anthropic. When a request is blocked, the user should be notified and the request can fall back to Claude Opus 4.8.
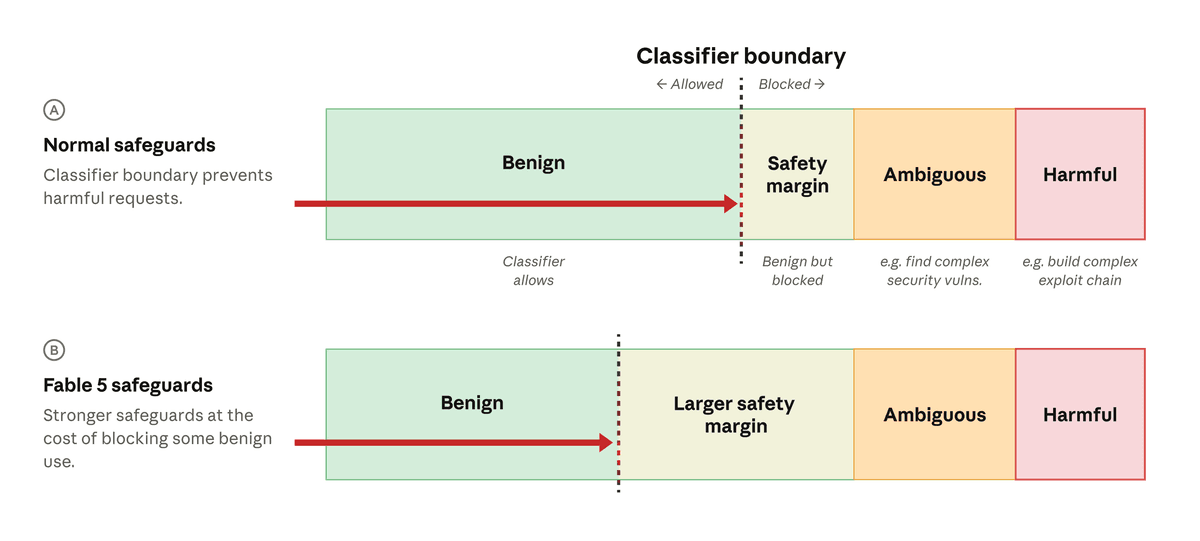
That fallback is important. It means some routine coding and debugging work may not hit Fable 5 at first. If the classifier sees a request as too close to cybersecurity, even when the user's intent is harmless, the task may go to Opus 4.8 instead.
I expect that to be annoying for developers in the short term. Debugging real systems often touches auth, networking, injection, dependencies, logs, and vulnerability language. A cautious classifier can easily mistake defensive engineering for misuse. Anthropic says it will refine the classifiers over the coming weeks to reduce false positives.
That is the right tradeoff if the alternative is losing access to Fable 5 again. Still, the practical question is not whether the classifier is philosophically correct. The question is whether it lets normal software work continue without forcing every security-adjacent task onto a different model.
Jailbreak severity needs a shared language
The more interesting policy move is the framework Anthropic is drafting with Amazon, Microsoft, Google, and other Glasswing partners. The goal is a shared way to judge how severe an AI jailbreak is and how model providers should respond.
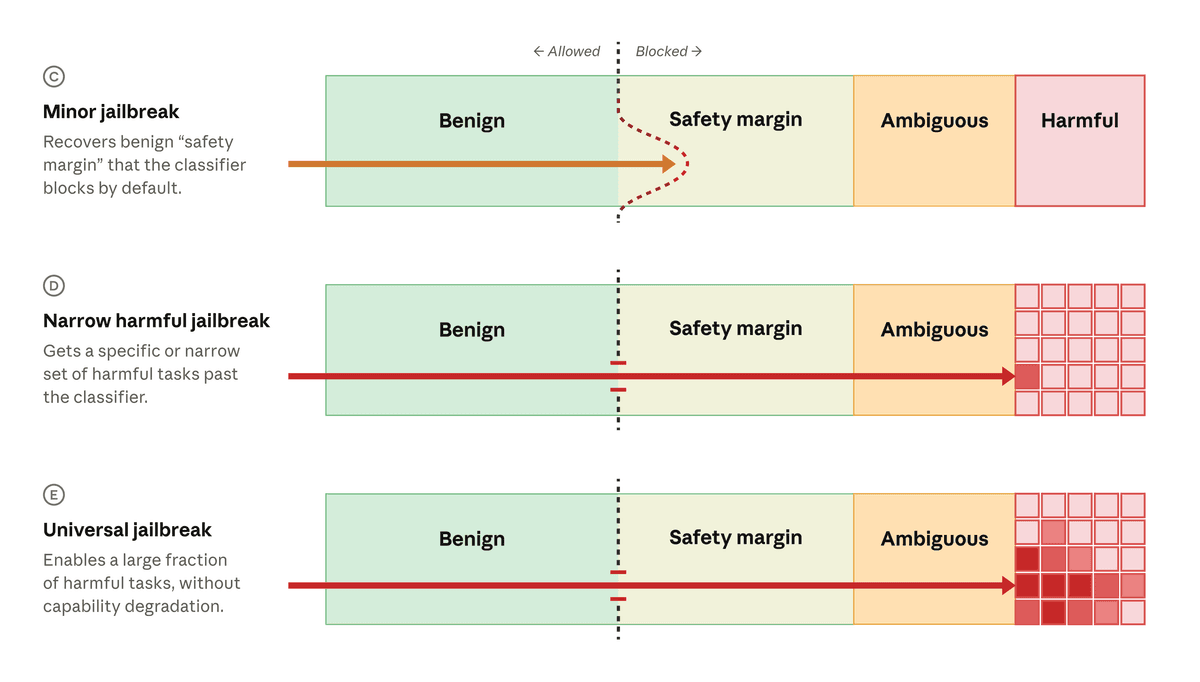
Anthropic's proposed criteria are sensible:
That matters because not every jailbreak has the same risk. A prompt that only recovers low-risk behavior inside the classifier safety margin is not the same as a universal jailbreak that unlocks a wide class of harmful capabilities. Treating both as the same kind of emergency creates bad incentives. Labs either overreact to small findings or under-explain the big ones.
A shared severity scale would not solve frontier-model safety by itself. It would at least make the conversation less chaotic.
My take
I want Fable 5 back because I want a model that feels worth reserving for the hard pass.
Sonnet 5 is now the sensible daily driver. I wrote about that in my Claude Sonnet 5 benchmark article→. It is cheaper, practical, and strong enough for many agent loops. Opus 4.8 still looks useful as a reliable fallback and review model.
Fable 5 sits in a different slot. I would use it when the task is expensive either way: a risky migration, a stuck bug, a deep repo review, a long agentic workflow, or a piece of analysis where the model has to hold many moving parts at once.
I also like that Anthropic is not pretending the redeploy is frictionless. The company is saying the new classifiers will create some false positives. That is better than selling the return as if nothing happened.
The test now is simple: can Fable 5 come back without becoming too jumpy to use for real engineering work?
If the answer is yes, I am happy this is over. I missed the model, and I want to put it back into the workflows where Sonnet is good but not enough.