
Short version: the OpenAI GPT-5.5 coding model feels different
The OpenAI GPT-5.5 coding model is the first Codex upgrade in a while where the improvement is not just raw capability. In my experience, I have tested it on real issue fixes and the main difference is control: it makes more targeted changes, edits less unrelated code, and often solves a well-scoped issue from one prompt.
OpenAI released GPT-5.5 on April 23, 2026, and the official launch frames it as the company's strongest agentic coding model so far. That is a big claim, but it matches the practical feel. The OpenAI GPT-5.5 coding model does not simply write more code. It seems better at understanding what should not change.
That is what impressed me most. The best coding agents are not the ones that generate the largest patch. They are the ones that fix the issue and leave the rest of the system stable.
What OpenAI officially announced
OpenAI describes GPT-5.5 as a model for complex, real-world work: writing and debugging code, researching online, analyzing data, creating documents and spreadsheets, operating software, and moving across tools until a task is finished. According to OpenAI, the model understands intent faster, uses fewer tokens on Codex tasks, and matches GPT-5.4 per-token latency in real-world serving.
Availability for Codex users
For developers, the key availability details are:
The important nuance: this article is about the OpenAI GPT-5.5 coding model as it works in Codex today, not a complete API migration plan yet.
Source: OpenAI, Introducing GPT-5.5.
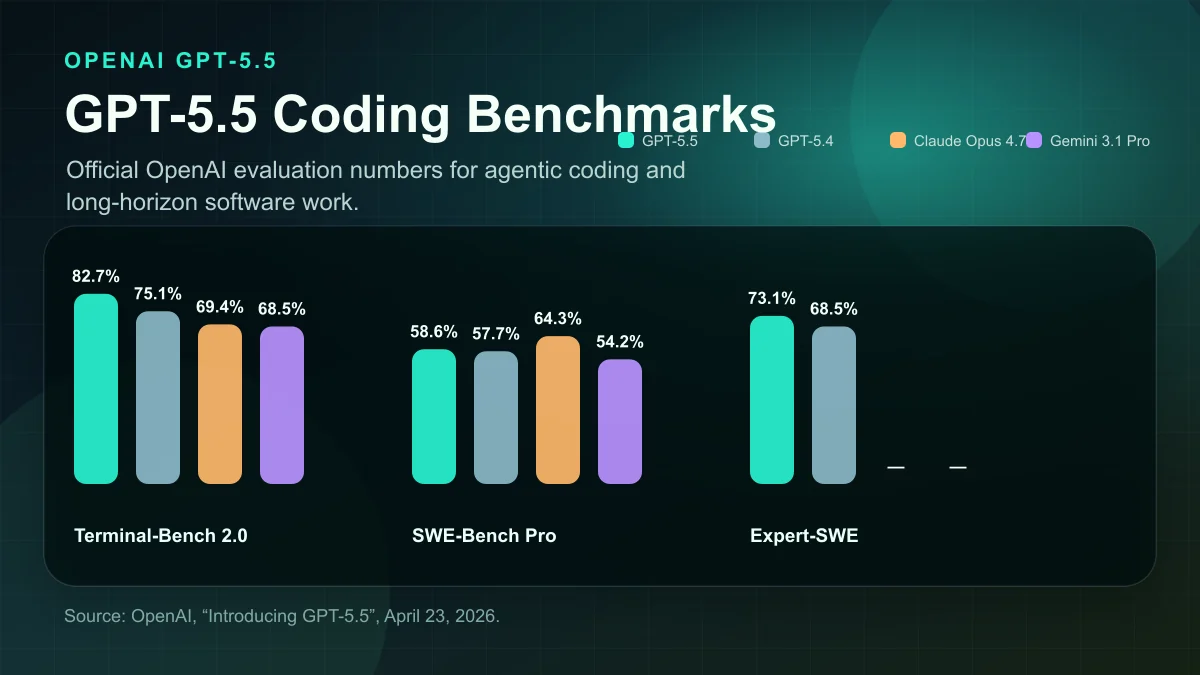
OpenAI GPT-5.5 coding model benchmarks
OpenAI published three coding-oriented results that matter for developers:
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| --- | ---: | ---: | ---: | ---: |
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| SWE-Bench Pro (Public) | 58.6% | 57.7% | 64.3% | 54.2% |
| Expert-SWE (Internal) | 73.1% | 68.5% | - | - |
Why Terminal-Bench matters
The Terminal-Bench 2.0 number is the cleanest public signal for agentic coding. Terminal-Bench tests command-line workflows where the model has to plan, run commands, coordinate tools, and iterate toward a result. That maps closely to how modern coding agents are actually used.
For the OpenAI GPT-5.5 coding model, 82.7% on Terminal-Bench 2.0 is the standout number. It is well ahead of GPT-5.4 in OpenAI's table and also ahead of the Claude and Gemini scores OpenAI included.
Why SWE-Bench needs caution
SWE-Bench Pro is still useful, but it needs caution. OpenAI itself notes that labs have found evidence of memorization on that eval. That does not make the score worthless, but it does mean I would not judge the whole model from SWE-Bench alone.
Expert-SWE is internal, so I treat it as OpenAI's own signal rather than an independently reproducible leaderboard. Still, the direction lines up with my hands-on testing: the OpenAI GPT-5.5 coding model feels stronger at long-horizon engineering tasks where context, restraint, and validation matter.
What other developers are saying
The external reaction I found lines up with my own testing.
CodeRabbit's early benchmark report says GPT-5.5 was quicker, leaner, and more direct in review workflows. Their practical takeaway was that the model produced better review signal, with more useful issues found and higher precision in their curated tests. That matches what I noticed: the OpenAI GPT-5.5 coding model is less noisy when the task is specific.

CodeRabbit reported these early review metrics:
| Review metric | Baseline | GPT-5.5 |
|---|---|---|
| --- | ---: | ---: |
| Expected issue found | 58.3% | 79.2% |
| Precision | 27.9% | 40.6% |
| Expected issue found (large-scale set) | 55.0% | 65.0% |
| Large-scale precision | 11.6% | 13.2% |
Source: CodeRabbit GPT-5.5 benchmark report.
Matt Shumer's review also points in the same direction: GPT-5.5 is strongest when the task is annoying, ambiguous, security-sensitive, design-constrained, or likely to break in subtle ways. His core point is that frontier coding models are already very strong, so the improvement shows up most clearly when you push the model into harder, messier work.
Source: Matt Shumer, My GPT-5.5 Review.
That is exactly the developer use case I care about. Not toy examples. Not one-file demos. Real codebases with existing conventions, weird edge cases, and a high cost for unrelated churn.
My hands-on impression in Codex
I have tested the OpenAI GPT-5.5 coding model in the kind of work that usually exposes model weaknesses: fixing review findings, changing one behavior without disturbing adjacent systems, keeping SEO/admin flows consistent, and validating the result instead of stopping at a plausible patch.
The biggest improvement is control.
Older coding models often solve the visible issue but create unnecessary surrounding change. They may rename too much, refactor too much, or turn a small bug fix into a broader redesign. GPT-5.5 feels more disciplined. It can still make mistakes, but it is more likely to touch the right files, preserve the existing style, and stop when the issue is actually fixed.
The behavior that matters
Most production work is not greenfield coding. Most production work is constrained editing. A good coding model should do five things:
The OpenAI GPT-5.5 coding model is not perfect, but it is noticeably better at that pattern.
The one-prompt issue fix is becoming real
The phrase "one prompt" can sound like hype, so I want to be precise. I do not mean that every serious engineering task should be solved with one lazy instruction. I mean that when the prompt includes the issue, the acceptance criteria, and the relevant constraints, GPT-5.5 often carries the task through without needing repeated corrections.
That is different from earlier workflows where you would ask for a fix, then ask it to undo unrelated changes, then ask it to run tests, then ask it to narrow the patch, then ask it to explain why a behavior changed.
What one-prompt success looks like
With the OpenAI GPT-5.5 coding model, I have seen more cases where the first attempt is already shaped correctly:
That is why it feels robust. The model is not only more capable; it is less chaotic.
Why targeted changes beat bigger rewrites
For coding agents, raw intelligence is only half the problem. The other half is restraint.
A model that changes 800 lines to fix a 20-line issue can look impressive in a demo but become expensive in a real repo. Every unnecessary change increases review time, test risk, merge conflict risk, and future debugging cost.
The OpenAI GPT-5.5 coding model seems better at local reasoning. It can inspect the surrounding system without feeling compelled to rewrite it. That makes it useful for:
This is also why benchmarks like Terminal-Bench matter. A coding agent has to work through a process, not just generate a function. It needs to use tools, interpret results, adjust, and avoid making a mess.
Where I would still be careful
GPT-5.5 is impressive, but I would not treat it as magic.
First, benchmarks are not the same as your codebase. Terminal-Bench and SWE-Bench are useful signals, but your repo has local conventions, hidden product decisions, old migrations, environment quirks, and tests that may or may not catch the real risk.
Second, the API was not available at launch. If your production automation depends on direct API access, the current practical path is Codex or ChatGPT until OpenAI opens gpt-5.5 in the API.
Third, stronger coding ability increases the need for better harnesses. A powerful model without tests, typed contracts, sandboxing, and review discipline can still ship the wrong thing faster.
Fourth, OpenAI's system card includes substantial safety evaluation around computer use, cyber, bio, hallucinations, and alignment. That matters because a more capable coding model can also perform more sensitive actions. Treat permissions, secrets, destructive commands, and production access seriously.
Source: OpenAI GPT-5.5 System Card.
My recommended GPT-5.5 coding workflow
For best results, I would use GPT-5.5 less like autocomplete and more like a focused engineering agent.
Prompt it like an engineer
Give it:
A strong prompt looks like this:
"Fix this issue with the smallest safe patch. Preserve existing route contracts, do not refactor unrelated code, and run the relevant type/lint/build checks before summarizing. If the fix requires a broader change, explain why before editing."
That kind of prompt fits the OpenAI GPT-5.5 coding model well because the model seems strong at carrying constraints through the whole task.
If you are working across multiple repositories or larger context windows, also make sure the model has a clean map of the system. I wrote about that in cross-repo AI context→, and it becomes more important as models get stronger.
So, is the OpenAI GPT-5.5 coding model worth using?
Yes. For real Codex work, the OpenAI GPT-5.5 coding model is one of the most impressive coding model upgrades I have tested.
The benchmark story is strong, especially Terminal-Bench 2.0. The external reviews point to the same practical pattern: more direct, more controlled, better signal. My own experience matches that. GPT-5.5 feels more robust, makes more targeted changes, changes less unrelated code around the fix, and often resolves issues from one well-scoped prompt.
That is the kind of improvement developers actually feel.
Not because it writes flashier code. Because it creates less cleanup after the code is written.


